


Differences Between Opus 4.6 and Opus 4.7
Claude Opus 4.7 is positioned as a major upgrade over Opus 4.6. The improvements are measurable, especially in coding benchmarks, document reasoning, tool usage, and visual understanding. However, the upgrade is not about becoming a completely new model. Instead, it focuses on discipline, accuracy, and reliability in long-running tasks.
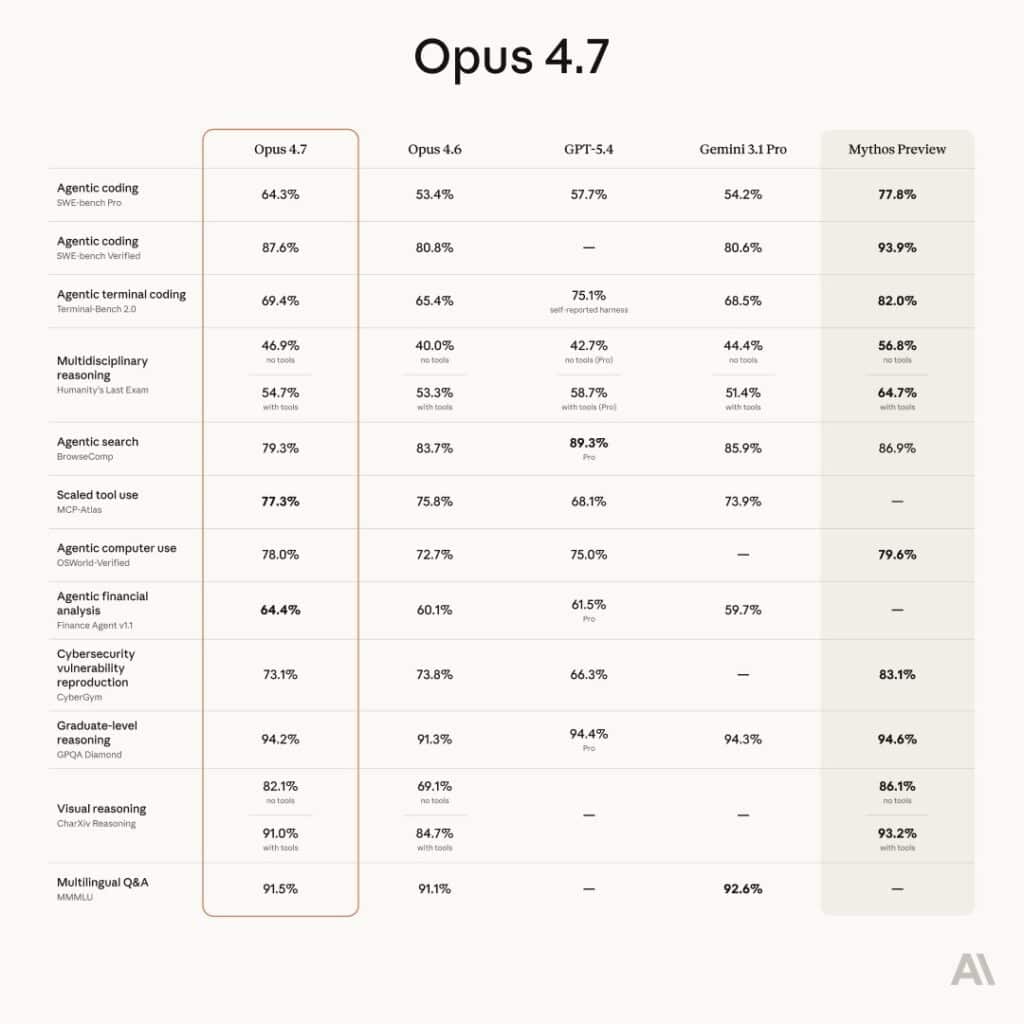
Main Differences Between Opus 4.6 and Opus 4.7: Claude Opus 4.7 is a significant upgrade over Opus 4.6, offering roughly 20% higher performance on coding (64.3% SWE-bench Pro) and stronger document reasoning, particularly in complex agentic workflows and tool-use tasks. While 4.7 features improved vision accuracy, a new tokenizer (using 1–1.35x more tokens) and more literal, precise prompting, it maintains the same $5/$25 pricing, making it a faster, more accurate drop-in replacement.
Comparison of Opus 4.7 vs Opus 4.6
Claude Opus 4.7 delivers:
- ~20% stronger coding performance
- 21% fewer reasoning errors
- Better agent workflows and tool usage
- Improved vision accuracy
- More precise instruction following
- Same pricing as Opus 4.6
The upgrade makes Opus 4.7 a direct replacement for Opus 4.6 in most workflows.
Why This Upgrade Matters
Many teams use AI models in production environments. Small accuracy gains can translate into major cost savings and faster development cycles. When an AI model produces fewer mistakes, it reduces:
- Debugging time
- Rework costs
- Human supervision
- Risk of production errors
Opus 4.7 focuses on reducing error rates rather than chasing headline benchmark jumps. This makes the upgrade more practical for real-world deployment.
Performance and Reasoning Improvements
One of the most important upgrades in Opus 4.7 is improved reasoning quality, especially in long documents and multi-step workflows.
Document reasoning benchmark improvement
Opus 4.7 shows 21% fewer errors on the OfficeQA Pro benchmark.
This matters because many enterprise workflows depend on AI to analyze:
- Contracts
- Reports
- Compliance documents
- Financial data
- Research papers
Reducing reasoning errors directly improves trust and usability.
Better multi-step reasoning
Opus 4.7 performs better when solving tasks that require:
- Planning
- Tool usage
- Iterative thinking
- Cross-document analysis
This is often called agentic workflow capability. These workflows are becoming standard in AI-powered applications.
Coding Performance Comparison
Coding improvements represent the most measurable upgrade.
SWE-bench Pro Results
Opus 4.7 achieved 64.3% on SWE-bench Pro.
This is roughly a 20% improvement over Opus 4.6.
What this means in practice
Opus 4.7 is better at:
- Debugging complex repositories
- Writing production-ready code
- Understanding large codebases
- Generating accurate patches
- Handling modern frameworks
Developers report fewer incorrect patches and better understanding of modern practices.
Modern CSS and frontend improvements
A notable improvement is better usage of modern CSS standards such as:
- :root variables
- Design systems
- Responsive layouts
- Semantic structure
This may sound minor, but it shows improved training on current development practices.
Real Benchmark Test: Zod 28 Task Experiment
A real-world experiment compared three models:
- March Opus 4.6
- Fresh Opus 4.6
- Opus 4.7
Raw pass rate result
All three models passed 12 out of 28 tasks.
At first glance, this suggests no improvement.
What actually changed
Above the pass threshold, the models diverged significantly.
Opus 4.7 produced:
- Higher quality patches
- Faster completion times
- Lower cost per task
- Better code equivalence
The key insight: Opus 4.7 is not categorically smarter. It is more disciplined and reliable.
This distinction matters more in production environments than raw benchmark scores.
Cost, Speed, and Efficiency
Performance gains are valuable only if they do not increase costs.
Pricing remains unchanged
Opus 4.7 keeps the same pricing:
- $5 input per million tokens
- $25 output per million tokens
Differences Between Opus 4.6 and Opus 4.7 – Cost per task comparison
| Metric | Opus 4.6 (March) | Opus 4.7 |
|---|---|---|
| Cost per task | $8.93 | $8.11 |
| Tokens used | 49.1M | 44.0M |
| Completion time | 1h 36m | 1h 30m |
Opus 4.7 is faster and cheaper per task despite using a new tokenizer.
Trending: ChatGPT vs Google Gemini Comparison 2026
Tokenizer Differences Between Opus 4.6 and Opus 4.7
Token usage increase
Opus 4.7 may use 1.0x to 1.35x more tokens for the same text.
This sounds negative but has tradeoffs:
Benefits:
- Better understanding of structure
- Improved reasoning accuracy
- Higher instruction precision
The result is better performance even if token counts increase slightly.
Instruction Following and Prompt Behavior
What changed
Opus 4.7:
- Interprets instructions more precisely
- Makes fewer assumptions
- Requires clearer prompts
Why this is good
Opus 4.6 sometimes guessed user intent. This occasionally helped beginners but caused inconsistencies in complex workflows.
Opus 4.7 behaves more like a professional engineer:
- Follows instructions strictly
- Asks fewer assumptions
- Produces predictable results
This reduces the need for prompt retries.
Vision and Image Understanding Improvements
Vision accuracy
Opus 4.7 reaches up to 98.5% accuracy in some visual tasks.
Improvements include:
- Higher resolution image support
- Better chart analysis
- Improved UI screenshot interpretation
- Stronger diagram understanding
This is especially valuable for:
- UI/UX design workflows
- Data visualization analysis
- Accessibility reviews
- Visual debugging
Vision is becoming critical for modern AI workflows.
Long Running Task Reliability
Opus 4.7 is designed for long-running autonomous tasks.
This includes:
- Project scaffolding
- Multi-file coding
- Research workflows
- Automated documentation
- Slide and prototype generation
The model verifies outputs before returning results. This reduces hallucinations and incomplete work.
Real Workflow Example: Website Generation Test
A test compared both models building a website using design and image plugins.
Observed improvements in Opus 4.7
- More creative design language
- Better structure and layout consistency
- Improved image generation integration
- More polished final output
Opus 4.7 produced a more refined and boutique-style website with stronger narrative tone and structure.
This shows improvement in creative + technical hybrid tasks and some Differences Between Opus 4.6 and Opus 4.7.
New Effort Levels and Token Usage
Opus 4.7 introduces a new extra high effort level.
Higher effort levels:
- Use more tokens
- Take longer
- Produce higher accuracy outputs
This gives developers better control over cost vs quality tradeoffs.
Who Should Upgrade to Opus 4.7?
Upgrade immediately if you:
- Use AI for coding
- Run long workflows
- Build AI agents
- Analyze documents
- Work with images or UI screenshots
Opus 4.6 may still work if you:
- Use short prompts only
- Have strict token limits
- Run simple automation tasks
For most users, Opus 4.7 is a drop-in replacement.
Key Differences Between Opus 4.6 and Opus 4.7:
- Performance & Reasoning: Opus 4.7 shows 21% fewer errors in document reasoning (Databricks’ OfficeQA Pro) and stronger agentic, multi-step coordination.
- Coding Improvements: Opus 4.7 provides a 13% improvement in coding, including better modern CSS practices (e.g., :root variables).
- Literal Instruction Following: 4.7 is more disciplined and literal than 4.6, often requiring less, but more precise, prompt tuning.
- Vision Capability: 4.7 offers superior vision accuracy (up to 98.5% in some tasks) with higher resolution support for charts and UI screenshots.
- Tokenization & Cost: 4.7 uses a new tokenizer, resulting in 1.0x to 1.35x more tokens for the same text compared to 4.6, although the per-token price remains the same.
Opus 4.7 represents a maturity upgrade rather than a radical redesign. For teams deploying AI in production, this type of improvement matters more than headline benchmark jumps.
FAQ Section
Is Opus 4.7 worth upgrading from 4.6?
Yes. The upgrade improves accuracy, speed, and cost efficiency without increasing pricing.
Does Opus 4.7 cost more to use?
No. Pricing remains the same as Opus 4.6.
Is Opus 4.7 better for coding?
Yes. It shows about 20% improvement on SWE-bench Pro.
Does Opus 4.7 use more tokens?
Yes. It may use up to 1.35x more tokens, but produces better results.
Is Opus 4.7 more intelligent?
It is more disciplined and reliable rather than fundamentally smarter.
Sources:






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment